Nội dung
Giới thiệu
Crawler là một công cụ giúp thu thập dữ liệu, thông tin từ các trang web khác nhau. Một trong những ví dụ về crawler mà chúng ta gặp hằng ngày là Google. Google là một hệ thống có nhiều máy chủ có thể crawling rất nhiều trang web trên Internet, từ đó chúng ta có thể tìm kiếm nội dung những trang web mà chúng ta cần dựa vào từ khoá cụ thể. Hoặc là những trang web so sánh giá cả từ nhiều nguồn khác nhau (websosanh.vn), trang tin báo tổng hợp (baomoi.com) và nhiều ví dụ khác mà mình không thể liệt kê hết ở đây.
Chúng ta có thể tự viết một crawler đơn giản nhằm thu gom một số dữ liệu cơ bản nào đó. Khi hướng dẫn học viên học module 2 (Advance Programming with Java) tại CodeGym, mình thường giao bài tập xây dựng công cụ crawler này. Ví dụ thu thập giá bất động sản trên các trang rao vặt hoặc giá sản phẩm trên các trang thương mại điện tử. Qua bài viết này, mình sẽ hướng dẫn lại các bạn làm bài tập này với ngôn ngữ lập trình Java.
Một số yêu cầu cơ bản để thực hiện bài tập này:
- Nắm vững cú pháp ngôn ngữ lập trình Java
- Sử dụng được ngôn ngữ đánh dấu HTML
- Sử dụng được biểu thức chính quy (regular expression) — còn được gọi là regex
- Một ít hiểu biết về HTTP (Giao thức được sử dụng để truy cập các trang web qua Internet)
- Hiểu cơ bản phương pháp lập trình hướng đối tượng
- Hiểu cơ bản về design pattern
Ghi chú: Trên thực tế, có nhiều thư viện hỗ trợ chúng ta làm crawler hiệu quả hơn cách làm trong bài này. Với mục đích học là chính, mình sẽ không sử dụng các thư viện đấy mà sẽ tự xây dựng lấy, các bạn nhé!
Thiết kế chương trình
Chúng ta sẽ xây dựng một công cụ có thể thu thập được tin tức bất động sản đang rao (bao gồm bán và cho thuê) tại các website sau:
- https://batdongsan.com.vn/
- https://batdongsan24h.com.vn/
- https://nhadat24h.net/
- https://diendanbatdongsan.vn/
Mô tả dữ liệu
Khai báo class có tên là ClassifiedAd để mô tả thông tin thu thập được từ các trang web. Bao gồm: tiêu đề, loại tin rao, diện tích, giá, mô tả chi tiết, hình ảnh (link).
Sau khi khảo sát nội dung các trang web, chúng ta thấy rằng:
- Các tin có thể hiển thị giá tổng (tính trên toàn bộ diện tích) hoặc giá theo mét vuông. Vì vậy cần khai báo những class sau để mô tả loại giá được hiển thị:
enum TypePrice,class Price. - Đơn vị tiền có thể là “triệu đồng” hoặc “tỷ đồng”. Vì vậy cần thuộc tính
unittương ứng trongclass Price. Giá trị được liệt kê trongenum Unitđể xác định đơn vị tiền tệ. - Các tin rao được phân loại thành: bán căn hộ, bán nhà đất, bán biệt thự, cho thuê,…
enum TypeAdđược khai báo cho mục đích này.
enum TypePrice {
PRICE_PER_M2, // loại giá dựa trên m2
TOTAL_PRICE // giá toàn bộ
}
enum Unit {
MILLION_VND,
BILLION_VND,
}
class Price {
private Float price;
private TypePrice typePrice;
private Unit unit;
}
enum TypeAd {
...,
SELL,
RENTAL,
OTHERS
}
class ClassifiedAd {
private String title; // tiêu đề
private TypeAd typeAd; // loại tin
private Price price; // giá
private Float acreage; // diện tích
private String description; // mô tả
}
Thiết kế tổng quan
Qua khảo sát các trang web mà cần thu thập tin, chúng ta có thể xác định thứ tự các bước để thu thập tin như sau:
- Truy cập trang chủ, liệt kê danh sách những danh mục tin (ví dụ: chung cư, nhà đất, biệt thự,…)
- Truy cập các danh mục tin để liệt kê các tin đang rao
- Truy cập trang chi tiết của từng tin để lấy các thông tin chi tiết
Chúng ta sẽ áp dụng pattern Template Method để chuyển các bước trên thành một dãy các bước xử lý chung cho mỗi trang web.
public abstract class Crawler {
// bước 1
abstract Iterable<Subpage> inspectHomepage();
// bước 2
abstract Iterable<DetailPage> inspectSubpage(Subpage subpage);
// bước 3
abstract ClassifiedAd inspectDetailPage(DetailPage detailPage);
// Đây là thao tác chung cho tất cả các trang web mà chúng ta muốn thu thập tin
Iterable<ClassifiedAd> inspect() {
List<ClassifiedAd> classifiedAds = new ArrayList<>();
Iterable<Subpage> subpages = inspectHomepage();
for (Subpage subpage: subpages) {
Iterable<DetailPage> detailPages = inspectSubpage(subpage);
for (DetailPage detailPage: detailPages) {
ClassifiedAd classifiedAd = inspectDetailPage(detailPage);
classifiedAds.add(classifiedAd);
}
}
return classifiedAds;
}
}
Với mỗi trang web cụ thể, chúng ta có một cách thu thập khác nhau (vì giao diện mỗi trang khác nhau). Trong tương lai, chúng ta có thể bổ sung những trang web khác hoặc thay đổi cách thức thu thập. Vì thế chúng ta sẽ xây dựng các class phục vụ việc crawle cho từng trang web cụ thể theo thiết kế như sau:
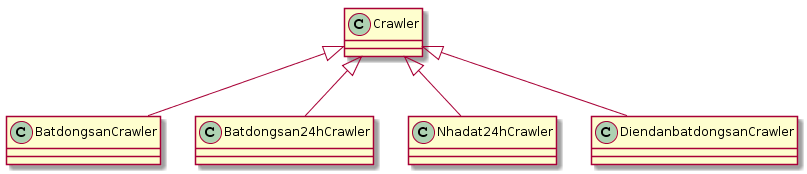
Sơ đồ lớp (class diagram) chương trình Crawler
Ở thiết kế trên, chúng ta áp dụng kiến thức về abstract class trong lập trình hướng đối tượng nhằm đảm bảo có thể dễ dàng mở rộng các trang web muốn thu thập. Khi cần bổ sung trang mới, chúng ta có thể implement thêm Crawler mà không phải sửa đổi ở khung thiết kế và luồng thực thi của chương trình. Cuối cùng là class MySimpleCrawler chứa đoạn mã khởi động chương trình.
Bây giờ, chúng ta viết mã kiểm tra xem ý tưởng thiết kế trên có thể thực hiện được chưa nhé! Tính năng ban đầu sẽ là khởi động chương trình và lấy những tin rao ở các trang batdongsan.com.vn.
Ghi chú: Ở công cụ siêu đơn giản này, chúng ta chưa tính đến việc làm thế nào để tối ưu thời gian chạy, lấy nhiều tin ở các trang tiếp theo, lên lịch chạy để luôn cập nhật được tin mới nhất, hoặc thậm chí là cấu hình thời gian ngắt quãng giữa các lần thu thập (để tránh trường hợp một số trang không cho phép tạo request liên tục trong khoảng thời gian nhất định nào đó).
Start coding!
1. Xác định các nội dung cần thu thập
Để lấy được nội dung trang web, chúng ta có thể sử dụng một tính năng tạo HTTP request đơn giản mà Java cung cấp là class URL.
Để tạo một request đến trang web cần lấy nội dung, chúng ta sử dụng hàm dưới đây:
private static String getContentFrom(String link) throws IOException {
// Gởi HTTP request và nhận về kết quả là chuỗi các thẻ HTML
URL url = new URL(link);
Scanner scanner = new Scanner(new InputStreamReader(url.openStream()));
scanner.useDelimiter("\\\\Z");
String content = scanner.next();
scanner.close();
// xoá các ký tự ngắt dòng (xuống dòng)
content = content.replaceAll("\\\\R", "");
return content;
}
Khi request thành công, các trang web thường trả về các thẻ HTML. Nếu nơi nhận là trình duyệt thì các thẻ HTML này sẽ được dựng hình (render) thành giao diện của trang web. Còn công cụ crawler của chúng ta chỉ xem đấy là các chuỗi ký tự. Việc chúng ta cần làm là tìm những vị trí chứa thông tin cần thiết bên trong chuỗi ấy. Biểu thức chính quy (regex) có thể được áp dụng trong trường hợp này.
Như vậy, chúng ta cần làm hai bước sau để lấy được thông tin trong trang web:
- Bước 1: Xác định vị trí thông tin cần lấy trong chuỗi HTML để tìm được quy tắc đánh dấu
- Bước 2: Dựa vào quy tắc đánh dấu trên, chúng ta xác định biểu thức chính quy phù hợp để lọc được chuỗi thông tin cần thiết
Để đơn giản hoá Bước 1 — Tìm vị trí các thông tin cần thiết trong chuỗi HTML trả về, chúng ta có thể sử dụng chức năng Inspect (trong bộ Developer Tools) của trình duyệt Google Chrome hoặc Firefox để tra đến vị trí mã nguồn thông qua giao diện trực quan.
Dưới đây là phần minh hoạ các bước trên cho việc liệt kê danh sách những danh mục tin ở trang chủ của trang web batdongsan.com.vn (Như đã trình bày Bước 1 trong mục Thiết kế tổng quan).
1.1. Hướng dẫn bước 1
- Truy cập trang web batdongsan.com.vn trên trình duyệt
- Mở chức năng Inspect với phím tắt Option + CMD + I (hệ điều hành MacOS) hoặc Ctrl + Shift + P (hệ điều hành Windows)
- Di chuyển chuột đến mục
Nhà đất bán>Bán căn hộ chung cưtrên thanh định hướng (menu) > Bấm chuột phải > Chọn Inspect.
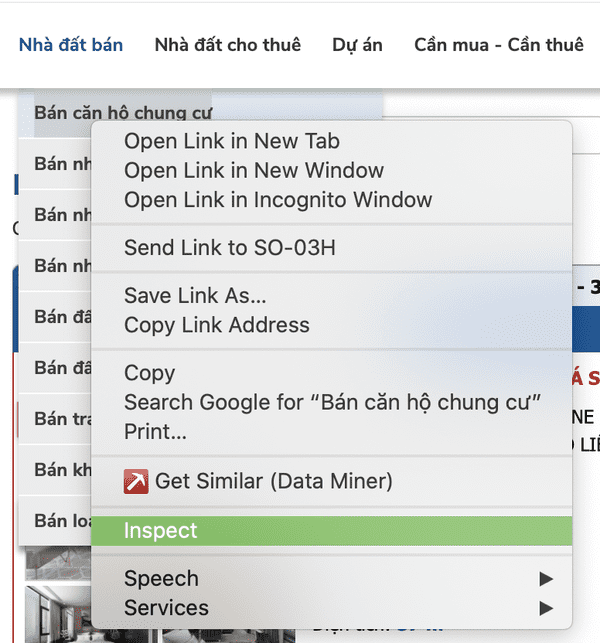
Rê chuột đến mục Nhà đất bán > Bán căn hộ chung cư trên thanh định hướng (menu), click chuột phải, chọn Inspect.
- Qua nội dung hiển thị trên tab Element, chúng ta có thể thấy mã HTML của những thẻ đánh dấu mục
Bán căn hộ chung cưnhư bên dưới:
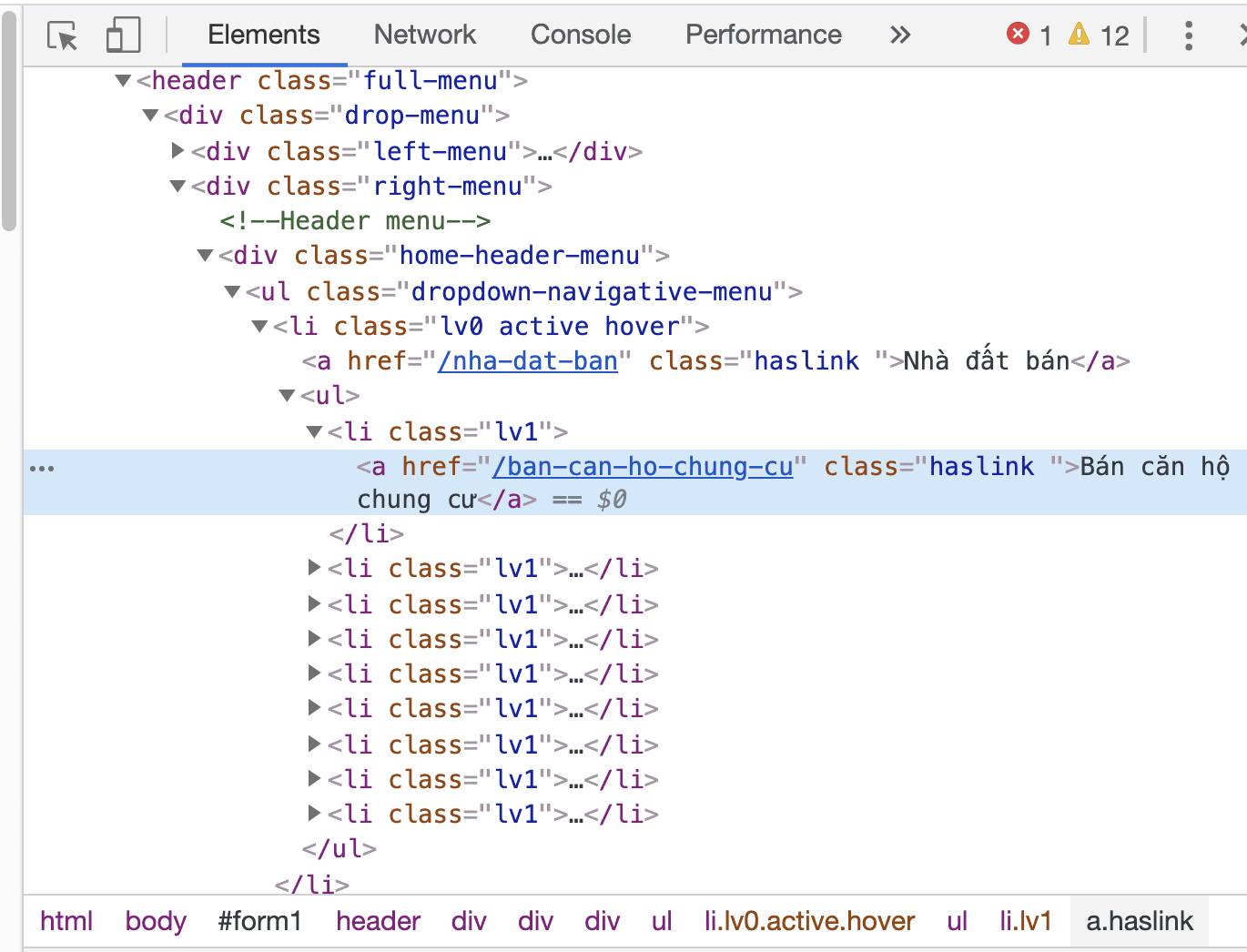
Qua nội dung hiển thị trên tab Element, chúng ta có thể thấy mã HTML của những thẻ đánh dấu mục Bán căn hộ chung cư như trên.
Như vậy, chúng ta xác định được mã đánh dấu các đường link của các danh mục tin trên trang web này là thẻ <a> nằm trong thẻ <li> có class là lv1.
1.2. Hướng dẫn bước 2
Qua bước 1, chúng ta xác định được rằng, để lấy được đường link của danh mục con Bán căn hộ chung cư thì phải lấy thuộc tính href của thẻ <a> nằm trong <li class="lv1">.
Vậy regex có thể dùng ở đây là:
"<li class='lv1'><a href='(.*?)' class='haslink '>"
Giá trị của thông tin mà chúng ta muốn tìm là đường link nằm giữa <li class='lv1'><a href=' và ' class='haslink '> được đại diện bằng các kí tự (.*?).
Bạn có thể kiểm tra kết quả tìm kiếm dựa trên regex trên bằng một chương trình demo nhỏ với những dòng mã sau:
public class DemoUsingURL {
private static String getContentFrom(String link) throws IOException {
...
}
public static void main(String[] args) throws IOException {
String content = getContentFrom("<https://batdongsan.com.vn>");
// Regex
Pattern p = Pattern.compile("<li class='lv1'><a href='(.*?)' class='haslink '>");
Matcher m = p.matcher(content);
while (m.find()) {
System.out.println(m.group(1));
}
}
}
Kết quả của đoạn code trên như sau:
/ban-can-ho-chung-cu /ban-nha-rieng /ban-nha-biet-thu-lien-ke /ban-nha-mat-pho /ban-dat-nen-du-an ... ... /phong-thuy-van-phong /tin-tuc-phong-thuy-theo-tuoi /nha-moi-gioi /doanh-nghiep
Đây là những đường link con, có thể kết hợp với chuỗi https://batdongsan.com.vn để tạo ra đường link dẫn tới nội dung các danh mục tin được rao.
Ở kết quả trên, chúng ta thấy có một số đường link không phù hợp. Vì đó là những đường link mà chúng ta không muốn thu thập nội dung. Ví dụ: /phong-thuy-van-phong, /tin-tuc-phong-thuy-theo-tuoi, /nha-moi-gioi,… Chúng ta sẽ tìm cách loại bỏ những kết quả không mong đợi này.
Xem xét lại mã HTML của trang web, chúng ta sẽ phát hiện ra các thẻ <li class='lv1'> chứa các thông tin cần thiết này nằm trong 2 nội dung sau:
Nhà đất bán
<li class='lv0'><a href="/nha-dat-ban" class="haslink ">Nhà đất bán</a> ...nội dung các danh mục con của mục Nhà đất bán ở đây </li>
Nhà đất cho thuê
<li class='lv0'><a href="/nha-dat-cho-thue" class="haslink ">Nhà đất cho thuê</a> ...nội dung các danh mục con của mục Nhà đất cho thuê ở đây </li>
Đoạn code trên cần sửa lại như dưới đây để loại ra những link không cần thiết:
public class DemoUsingURL {
private static String getContentFrom(String link) throws IOException {
...
}
private static List<String> getLinksFromMenu(String content, String menuPattern) {
// Regex
List<String> links = new ArrayList<>();
Pattern p = Pattern.compile(menuPattern);
Matcher m = p.matcher(content);
while (m.find()) {
Pattern p2 = Pattern.compile("<li class='lv1'><a href='(.*?)' class='haslink '>");
Matcher m2 = p2.matcher(m.group(1));
while (m2.find()) links.add(m2.group(1));
}
return links;
}
public static void main(String[] args) throws IOException {
String content = getContentFrom("<https://batdongsan.com.vn>");
String sellMenuPattern = "<li class='lv0'><a href='/nha-dat-ban' class='haslink '>Nhà đất bán</a><ul>(.*?)</ul>";
List<String> sellLinks = getLinksFromMenu(content, sellMenuPattern);
String rentalMenuPattern = "<li class='lv0'><a href='/nha-dat-cho-thue' class='haslink '>Nhà đất cho thuê</a><ul>(.*?)</ul>";
List<String> rentalLinks = getLinksFromMenu(content, rentalMenuPattern);
System.out.println(sellLinks);
System.out.println(rentalLinks);
}
}
Ở đoạn code trên, mình tách phần lấy nội dung từ đường dẫn trang web thành hàm getContentFrom, và một hàm tách link từ nội dung có tên là getLinksFromMenu. Hàm main sử dụng hai hàm được khai báo ở trên để lấy các đường link nằm trong mục Nhà đất bán và Nhà đất cho thuê.
1.3. Thực hành
Bây giờ, các bạn có thể tự thực hành với hướng dẫn hai bước trên để xác định những thông tin còn lại.
Nếu cần có kết quả ngay thì bạn có thể tham khảo mã nguồn mình cung cấp ở cuối bài viết này! 🙂
1.4. Tổng hợp các regex tìm được
Dưới đây các regex đã tìm được với trang batdongsan.com.vn để các bạn tham khảo:
- Link các danh mục tin
- Link đến nội dung chi tiết
- Thông tin cụ thể (như tiêu đề, giá, diện tích,…) trong tin chi tiết
1.4.1. Link các danh mục tin
Tìm các link bên trong mục “Nhà đất bán” và “Nhà đất cho thuê”:
Pattern p1 = Pattern.compile("<li class='lv0'><a href='/nha-dat-ban' class='haslink '>Nhà đất bán</a><ul>(.*?)</ul>");
Pattern p2 = Pattern.compile("<li class='lv0'><a href='/nha-dat-cho-thue' class='haslink '>Nhà đất cho thuê</a><ul>(.*?)</ul>");
Sau đó, tìm các link danh mục thuộc “Nhà đất bán” và “Nhà đất cho thuê” để loại các link không cần thiết:
Pattern pLink = Pattern.compile("<li class='lv1'><a href='(.*?)' class='haslink '>");
1.4.2. Link đến nội dung chi tiết
Pattern p = Pattern.compile("<div class='p-title'><h3><a href='(.*?)' title");
1.4.3. Thông tin cụ thể trong tin chi tiết
String title = "<h1 itemprop=\\"name\\">(.*?)</h1>"; String price = "<span class=\\"gia-title mar-right-15\\"><b>Giá:</b><strong>(.*?)</strong>";Pattern p = Pattern.compile(title + ".*" + price);
2. Viết mã crawler cho từng trang web cụ thể
Xác định được các regex pattern để lấy những thông tin cần thiết ở trên là chúng ta đã đi được 50% chặng đường. Việc còn lại là kết hợp các regex trên để viết mã crawler cụ thể cho từng trang web theo thiết kế được trình bày trong mục Thiết kế tổng quan.
Các class dành cho trang cụ thể sẽ implement những phương thức abstract đã định nghĩa trong Crawler:
// bước 1
abstract Iterable<Subpage> inspectHomepage();
// bước 2
abstract Iterable<DetailPage> inspectSubpage(Subpage subpage);
// bước 3
abstract ClassifiedAd inspectDetailPage(DetailPage detailPage);
inspectHomepage() sẽ sử dụng các regex như minh hoạ trong mục Hướng dẫn bước 1.
inspectSubpage trả về danh sách link các trang chi tiết.
inspectDetailPage trả về thông tin cụ thể từ trang chi tiết.
Cải tiến
Như đã trình bày ở trên, đây là một công cụ “siêu đơn giản”. Vì thế sẽ thiếu nhiều tính năng để crawler thực sự hữu ích trên thực tế như tối ưu thời gian chạy, lên lịch chạy để luôn cập nhật được tin mới nhất, lưu vào kho dữ liệu phù hợp phục vụ tra cứu hoặc tính toán/so sánh…
Mình sẽ đưa ra một số gợi ý để các bạn có thể tiếp tục tìm hiểu và cải tiến công cụ này nhé!
- Sử dụng Thread để tối ưu thời gian chạy, giảm thời gian đợi giữa các lần request nội dung từng trang web. Vì mỗi trang được xử lý độc lập, việc đợi kết quả của request này sẽ không ảnh hưởng đến kết quả của các request còn lại.
- Sử dụng Crob Job để lên lịch chạy hằng ngày hoặc một khung thời gian cố định (ví dụ: 10 phút 1 lần). Hiện tại, các thao tác phải được kích hoạt thủ công. Việc này sẽ không giúp hệ thống có được dữ liệu mới nhất.
- Sử dụng một hệ CSDL cụ thể để gom dữ liệu thu thập được. Hệ CSDL sẽ giúp chúng ta có thể xử lý và đưa ra một số thông tin hữu ích. Ví dụ: so sánh giá thị trường với từng khu vực cụ thể, hoặc tìm giá tốt nhất được rao trên các trang theo nhu cầu của người dùng.
Author: Đặng Huy Hòa
XEM THÊM CÁC TÀI LIỆU KHÁC TẠI ĐÂY.
















0 Lời bình